
.read_excel() 方法
读取excel
- sheet_name可以是int类型,就是按照数字来读取工作表。也可以是str类型,就是输入表的名称,读取这个工作表
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
df2 = pd.read_excel('pandas测试.xlsx', sheet_name='Sheet1')
print(df)
print(df2)
指定哪几行作为表头
-
header 可以指定哪几行作为表
使用.columns 打印查看列信息
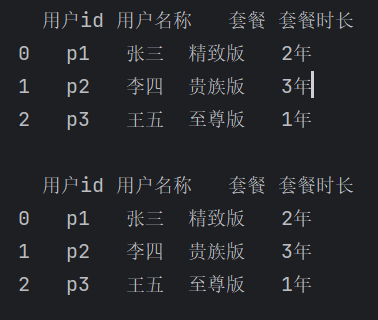
df = pd.read_excel('crm接口.xlsx', sheet_name = 0, header = [0,1])
print(df)
print(df.columns)
自定义表头
- names 可以自定义表头,会替代原来的列表头,长度必须和原来的一样
df = pd.read_excel('pandas测试.xlsx', sheet_name = 0, names=['自定义1','自定义2','自定义3','自定义4'])
print(df)
print(df.columns)

指定列 作为行索引
- index_col 指定那一列作为行索引
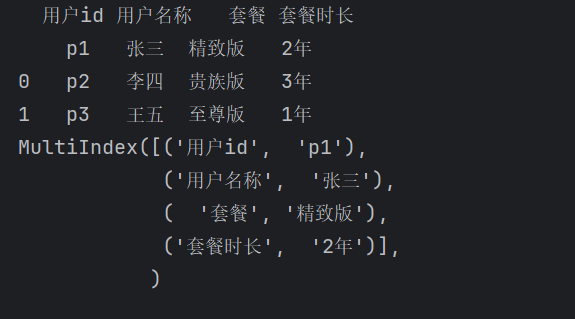
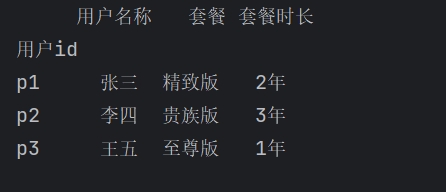
df = pd.read_excel('pandas测试.xlsx', sheet_name=0, index_col='用户id')
print(df)
指定读取哪几列
- usecols 指定读取哪几列,可以是下标数字,也可以是excel里的列标识:A B C D
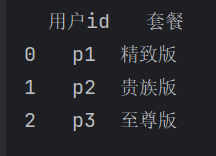
df = pd.read_excel('pandas测试.xlsx', sheet_name=0, usecols=[0,2])
df1 = pd.read_excel('pandas测试.xlsx', sheet_name=0, usecols="A,C")
print(df)
指定读取前多少行
- nrows 表示只读取excel的 前nrows行,包括表头
# 读取前2行
df = pd.read_excel('pandas测试.xlsx', sheet_name=0, nrows=2)
print(df)

读取 跳过前多少行&跳过指定行
- skiprows 读取时 跳过行,表头也算,如果是int类型,则跳过前指定行。如果是列表[ ],则跳过第 指定行+1 行
# 跳过前1行
df1 = pd.read_excel('pandas测试.xlsx', sheet_name=0, skiprows=1)
print(df1)
# 跳过第 1+1 行
df2 = pd.read_excel('pandas测试.xlsx', sheet_name=0, skiprows=[1])
print(df2)
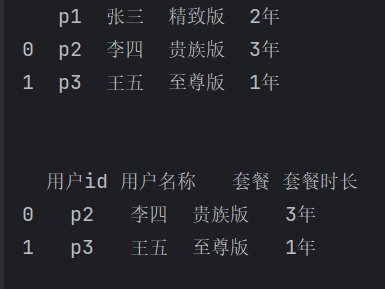
获取行列索引值
df = pd.read_excel('pandas测试.xlsx', sheet_name = 0, index_col='用户id')
# 获取 行列索引值
print(list(df.index))
print(list(df.columns))
print()
# 获取指定 行列索引值
print(df.index[1])
print(list(df.index[1:3]))
print(df.columns[1])
print(list(df.columns[1:3]))

打印行列和某个元素的数据
指定打印获取列数据
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
print(df['用户名称']) # 按列名取列数据
print(df.用户名称) # 按列名取列数据
print()
print(df[['套餐', '套餐时长']]) # 按列名取不连续列数据
print(df[df.columns[1:4]]) # 按列索引取连续列数据
print()
print(df.iloc[:, 1]) # 按位置取列,第1列,从0列开始数
print(df.iloc[:, [1, 3]]) # 按位置取不连续列数据
print()
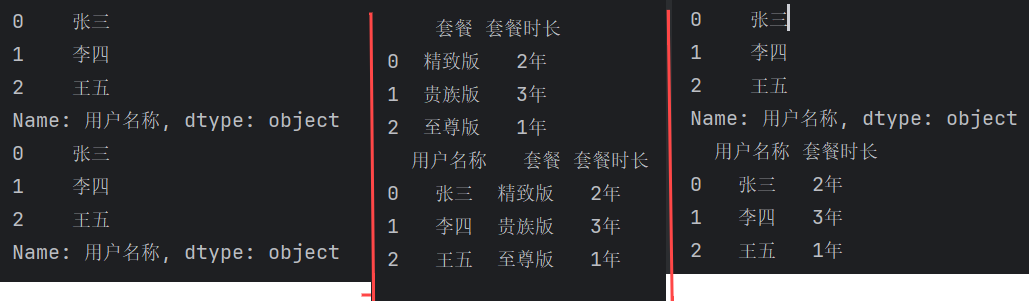
指定打印获取行数据
iloc方法
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
print(df[1:3]) # 按行取数据,列索引不算一行
print(df[df.套餐 == '至尊版']) # 按行有条件的取数据,取套餐等于 '至尊版' 的行。(还可以比较数字的大小)
print(df.iloc[1]) # 按行取行数据
print(df.iloc[1:3]) # 按行取连续数据
print(df.iloc[[1, 2]]) # 按行取不连续数据
print(df.iloc[[1, 2], [1, 3]]) # 取部分行 部分列数据

loc方法
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
print(df.loc[2]) # 取行,2是行索引,也可以是str类型,下同
print(df.loc[2, '套餐']) # 取某个元素
print(df.loc[0:2]) # 取连续的行
print(df.loc[[0,2]]) # 取某几行
print(df.loc[df.index[1:2]]) # 按行索引取行
print(df.loc[[0, 2], ['用户名称', '套餐']]) # 取行和列的交集

.head()
.head() 可以指定打印前几行
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
print(df.head(2))

获取某一个元素数据
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
print(df.iloc[0, 2]) # 按坐标取
print(df.iloc[[0], [2]]) # 按坐标取
print(df.loc[[0, 2], ['套餐', '套餐时长']]) # 取行和列的交集
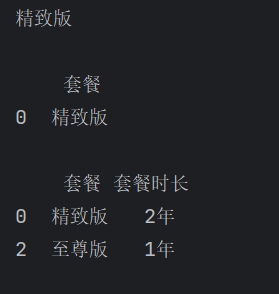
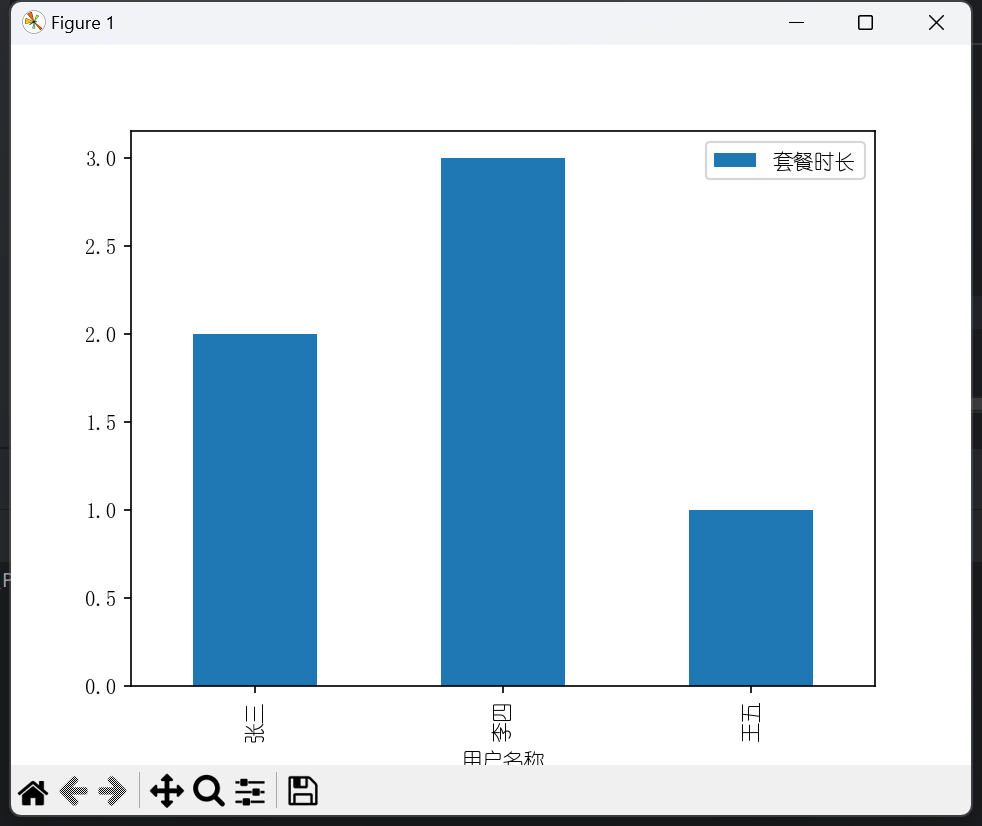
画图
import pandas as pd
import matplotlib.pyplot as plt
plt.rc("font",family='YouYuan') # 选择中文字体,否则不显示中文
df = pd.read_excel('pandas测试.xlsx', sheet_name=0)
df.plot(x='用户名称', y='套餐时长', kind='bar')
plt.show()
【pandas】对 excel 的操作
https://hilxy.com/archives/52308653-ee49-48e4-ba6b-f05913f4c001
评论