

# coding=utf-8
import requests
from tqdm import tqdm
# 要下载文件的URL
url = "https://pan.hilxy.com/d/%E5%BD%B1%E9%9F%B3%E8%A7%86%E5%90%AC/MV/%E5%BC%A0%E6%9D%B0%20%E9%80%86%E6%88%98%20MV.mp4"
# 使用streaming模式发送GET请求
res = requests.get(url, stream=True)
# 从Content-Length头部获取文件总大小(字节)
file_size_bytes = int(res.headers.get('Content-Length', 0))
# 将字节转换为MB,用于进度条显示
file_size_mb = file_size_bytes / (1024 * 1024)
'''
total:设置文件大小
unit:单位
leave:是否在完成后继续显示进度条
desc:进度条前缀描述
'''
# 初始化进度条,设置单位为:MB,并在下载完成后显示描述,并设置前缀为:正在下载...
pbar = tqdm(total=file_size_mb, unit='MB', leave=True, desc='正在下载...')
# 以二进制模式打开文件准备写入
with open('电影下载.mp4', 'wb') as f:
# 迭代响应内容,每次获取一个数据块
for chunk in res.iter_content(chunk_size=1024*1024*2): # 每次获取2MB的数据块
if chunk: # 检查数据块是否为空(对于保持连接的空数据块进行过滤)
f.write(chunk) # 将数据块写入文件
# 根据数据块的实际大小(MB)更新进度条
chunk_size_mb = len(chunk) / (1024 * 1024)
pbar.update(chunk_size_mb) # 更新进度条
pbar.set_description('下载完成')
# 注意:在这个例子中,我们不需要手动调用pbar.close(),因为with语句结束时tqdm会自动处理。
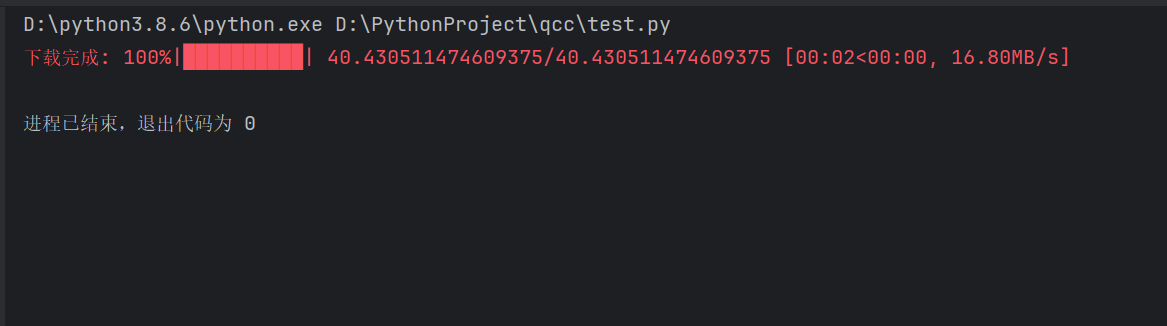
requests 流下载 + 进度条
https://hilxy.com/archives/8ff49fba-7ce9-4206-8aea-4c9cf646b35a
评论