
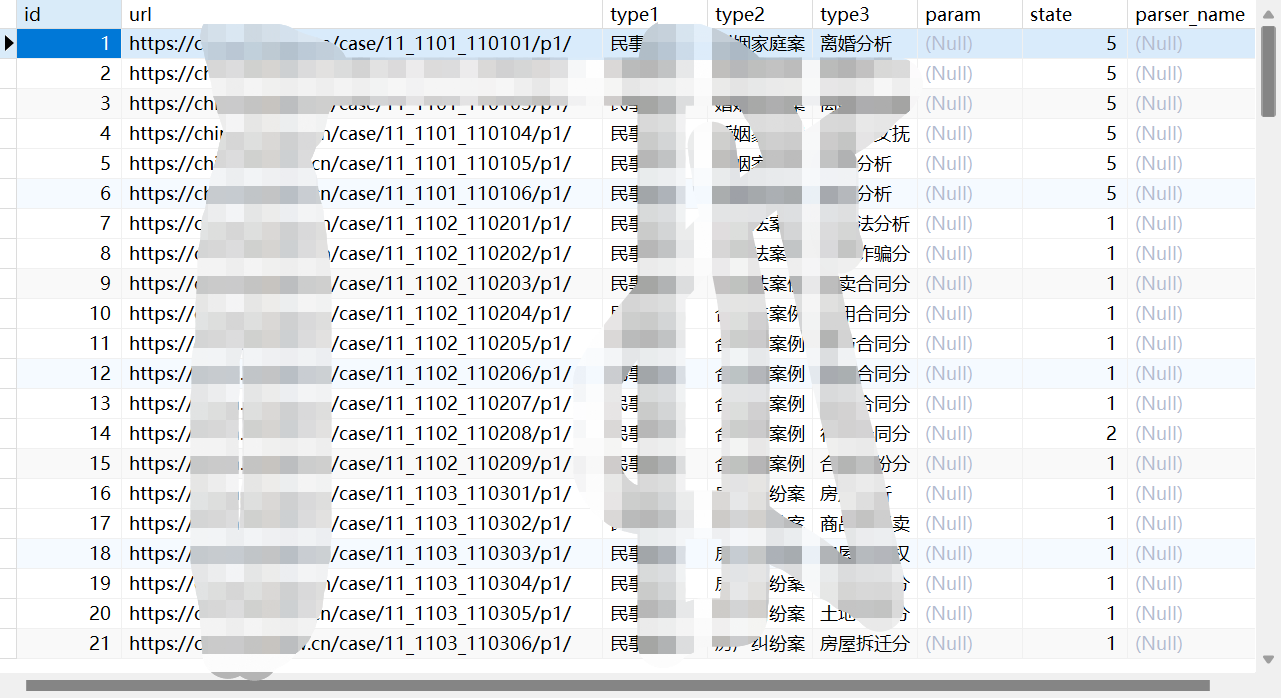
把这些案例的url放到mysql任务表里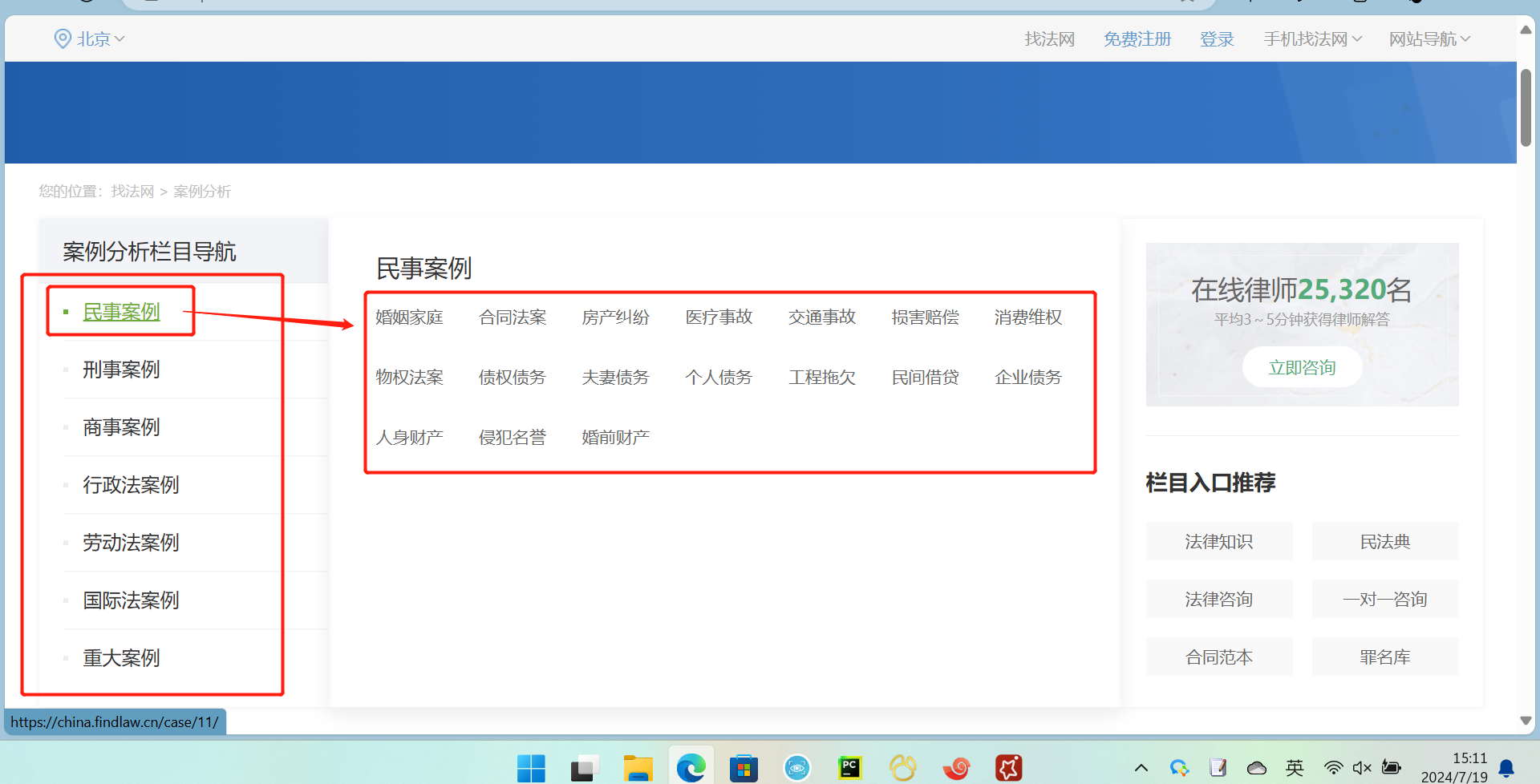
spider代码
# -*- coding: utf-8 -*-
"""
Created on 2024-07-11 15:29:07
---------
@summary:
---------
@author: fb
"""
import feapder
from feapder import ArgumentParser
from items import *
class FindlawCase(feapder.TaskSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
# 是否去重
ITEM_FILTER_ENABLE=False,
# 日志级别
# LOG_LEVEL="DEBUG",
)
def start_requests(self, task):
task_id = task.id
url = task.url
type1 = task.type1
type2 = task.type2
type3 = task.type3
yield feapder.Request(url, task_id=task_id,type1=type1,type2=type2,type3=type3)
# 解析函数
def parse(self, request, response):
now_page = int(response.url.split('/p')[1].replace('/',''))
end_url = response.bs4().find('div',class_='page')
if end_url is None:
end_page = 1
else:
end_url2 = end_url.find_all('a')[-1].get('href')
end_page = int(end_url2.split('/p')[1].replace('/',''))
type1 = request.type1
type2 = request.type2
type3 = request.type3
case_list = response.bs4().find('ul',class_="dj-ctlist-ul").find_all('li')
for i in case_list:
details_url = i.find('a').get('href')
yield feapder.Request(details_url, callback=self.details_patse,task_id=request.task_id, type1=type1, type2=type2, type3=type3)
if now_page != end_page:
next_url = response.url.split('/p')[0] + f'/p{now_page+1}/'
yield feapder.Request(next_url, task_id=request.task_id, type1=type1, type2=type2, type3=type3)
# mysql 需要更新任务状态为做完 即 state=1
yield self.update_task_batch(request.task_id)
# 校验函数
def validate(self, request, response):
if response.status_code == 404:
return False # 抛弃当前请求
# 详情解析函数
def details_patse(self,request,response):
item = findlaw_case_item.FindlawCaseItem()
contents = response.bs4().find('div',class_="tablistBox")
title = response.bs4().find('h1',class_="lefttlt").text
item['title'] = title
try:
item['aq_introduce'] = (contents.find('div',id="tablist0").text).replace('[案情介绍]\n','')
except:
item['aq_introduce'] = None
try:
item['aq_analyse'] = (contents.find('div',id="tablist1").text).replace('[案情分析]\n','')
except:
item['aq_analyse'] = None
if item['aq_introduce'] is None and item['aq_analyse'] is None:
return False
try:
item['judgment_result'] = (contents.find('div',id="tablist2").text).replace('[判决结果]\n','')
except:
item['judgment_result'] = None
try:
item['relate_to_law'] = (contents.find('div',id="tablist3").text).replace('[相关法规]\n','')
except:
item['relate_to_law'] = None
item['type1'] = request.type1
item['type2'] = request.type2
item['type3'] = request.type3
item['url'] = response.url
item['unique_id'] = 'findlaw_case_' + response.url.replace('https://china.findlaw.cn/case/','').replace('.html','')
item['source'] = '找法网案例分析'
yield item
if __name__ == "__main__":
# 用mysql做任务表,需要先建好任务任务表
spider = FindlawCase(
redis_key="case:findlaw_case", # 分布式爬虫调度信息存储位置
task_table="findlaw_case_task", # mysql中的任务表
task_keys=["id", "url", "type1", "type2", "type3"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
)
# 用redis做任务表
# spider = FindlawCase(
# redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
# task_table="", # 任务表名
# task_table_type="redis", # 任务表类型为redis
# )
parser = ArgumentParser(description="FindlawCase爬虫")
parser.add_argument(
"--start_master",
action="store_true",
help="添加任务",
function=spider.start_monitor_task,
)
parser.add_argument(
"--start_worker", action="store_true", help="启动爬虫", function=spider.start
)
parser.start()
# 直接启动
spider.start() # 启动爬虫
# spider.start_monitor_task() # 添加任务
# 通过命令行启动
# python findlaw_case.py --start_master # 添加任务
# python findlaw_case.py --start_worker # 启动爬虫
setting.py代码
# -*- coding: utf-8 -*-
"""爬虫配置文件"""
# import os
# import sys
#
# # MYSQL
MYSQL_IP = "***"
MYSQL_PORT = ***
MYSQL_DB = "***"
MYSQL_USER_NAME = "***"
MYSQL_USER_PASS = "***"
# # MONGODB
# MONGO_IP = "localhost"
# MONGO_PORT = 27017
# MONGO_DB = ""
# MONGO_USER_NAME = ""
# MONGO_USER_PASS = ""
#
# # REDIS
# # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"]
REDISDB_IP_PORTS = "***"
REDISDB_USER_PASS = "***"
REDISDB_DB = 15
# # 连接redis时携带的其他参数,如ssl=True
# REDISDB_KWARGS = dict()
# # 适用于redis哨兵模式
# REDISDB_SERVICE_NAME = ""
#
# # 数据入库的pipeline,可自定义,默认MysqlPipeline
# ITEM_PIPELINES = [
# "feapder.pipelines.mysql_pipeline.MysqlPipeline",
# # "feapder.pipelines.mongo_pipeline.MongoPipeline",
# # "feapder.pipelines.console_pipeline.ConsolePipeline",
# ]
# EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警
# EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试
#
# # 爬虫相关
# # COLLECTOR
COLLECTOR_TASK_COUNT = 5 # 每次获取任务数量,追求速度推荐32
#
# # SPIDER
SPIDER_THREAD_COUNT = 5 # 爬虫并发数,追求速度推荐32
# # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5
SPIDER_SLEEP_TIME = [40,120]
SPIDER_MAX_RETRY_TIMES = 2 # 每个请求最大重试次数
# KEEP_ALIVE = False # 爬虫是否常驻
# 下载
# DOWNLOADER = "feapder.network.downloader.RequestsDownloader" # 请求下载器
# SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader"
# RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader" # 渲染下载器
# # RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader"
# MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接
# # 浏览器渲染
# WEBDRIVER = dict(
# pool_size=1, # 浏览器的数量
# load_images=True, # 是否加载图片
# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
# headless=False, # 是否为无头浏览器
# driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
# timeout=30, # 请求超时时间
# window_size=(1024, 800), # 窗口大小
# executable_path=None, # 浏览器路径,默认为默认路径
# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
# custom_argument=[
# "--ignore-certificate-errors",
# "--disable-blink-features=AutomationControlled",
# ], # 自定义浏览器渲染参数
# xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
# auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
# download_path=None, # 下载文件的路径
# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
# )
#
# PLAYWRIGHT = dict(
# user_agent=None, # 字符串 或 无参函数,返回值为user_agent
# proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
# headless=False, # 是否为无头浏览器
# driver_type="chromium", # chromium、firefox、webkit
# timeout=30, # 请求超时时间
# window_size=(1024, 800), # 窗口大小
# executable_path=None, # 浏览器路径,默认为默认路径
# download_path=None, # 下载文件的路径
# render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
# wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle"
# use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
# page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()}
# storage_state_path=None, # 保存浏览器状态的路径
# url_regexes=None, # 拦截接口,支持正则,数组类型
# save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口
# )
#
# # 爬虫启动时,重新抓取失败的requests
RETRY_FAILED_REQUESTS = True
# # 爬虫启动时,重新入库失败的item
# RETRY_FAILED_ITEMS = False
# # 保存失败的request
SAVE_FAILED_REQUEST = True
# # request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做)
# REQUEST_LOST_TIMEOUT = 600 # 10分钟
# # request网络请求超时时间
# REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组
# # item在内存队列中最大缓存数量
# ITEM_MAX_CACHED_COUNT = 5000
# # item每批入库的最大数量
# ITEM_UPLOAD_BATCH_MAX_SIZE = 1000
# # item入库时间间隔
ITEM_UPLOAD_INTERVAL = 1
# # 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。
# TASK_MAX_CACHED_SIZE = 0
#
# # 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求
# RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True
# RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒
# RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True
# # 设置代理
# PROXY_EXTRACT_API = "1111" # 代理提取API ,返回的代理分割符为\r\n
# PROXY_ENABLE = True
# PROXY_MAX_FAILED_TIMES = 1 # 代理最大失败次数,超过则不使用,自动删除
# PROXY_POOL = "my_proxy_pool.MyProxyPool" # 代理池
#
# # 随机headers
RANDOM_HEADERS = True
# # UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型
USER_AGENT_TYPE = "chrome"
# # 默认使用的浏览器头
# DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
# # requests 使用session
# USE_SESSION = False
#
# # 去重
ITEM_FILTER_ENABLE = True # item 去重
# REQUEST_FILTER_ENABLE = False # request 去重
# ITEM_FILTER_SETTING = dict(
# filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4
# )
# REQUEST_FILTER_SETTING = dict(
# filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4
# expire_time=2592000, # 过期时间1个月
# )
#
# # 报警 支持钉钉、飞书、企业微信、邮件
# # 钉钉报警
# DINGDING_WARNING_URL = "" # 钉钉机器人api
# DINGDING_WARNING_PHONE = "" # 被@的群成员手机号,支持列表,可指定多个。
# DINGDING_WARNING_USER_ID = "" # 被@的群成员userId,支持列表,可指定多个
# DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False
# DINGDING_WARNING_SECRET = None # 加签密钥
# # 飞书报警
# # https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f
# FEISHU_WARNING_URL = "" # 飞书机器人api
# FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}]
# FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False
# # 邮件报警
EMAIL_SENDER = "***" # 发件人
EMAIL_PASSWORD = "***" # 授权码
EMAIL_RECEIVER = "***" # 收件人 支持列表,可指定多个
EMAIL_SMTPSERVER = "***" # 邮件服务器 默认为163邮箱
# # 企业微信报警
# WECHAT_WARNING_URL = "" # 企业微信机器人api
# WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人
# WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False
# # 时间间隔
# WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重
# WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR
# WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警
#
# LOG_NAME = os.path.basename(os.getcwd())
# LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径
LOG_LEVEL = "INFO"
# LOG_COLOR = True # 是否带有颜色
# LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台
# LOG_IS_WRITE_TO_FILE = False # 是否写文件
# LOG_MODE = "w" # 写文件的模式
# LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数
# LOG_BACKUP_COUNT = 20 # 日志文件保留数量
# LOG_ENCODING = "utf8" # 日志文件编码
# OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级
#
# # 切换工作路径为当前项目路径
# project_path = os.path.abspath(os.path.dirname(__file__))
# os.chdir(project_path) # 切换工作路经
# sys.path.insert(0, project_path)
# print("当前工作路径为 " + os.getcwd())
feapder-【某法网】的案例
https://hilxy.com/archives/feapder--mou-fa-wang-de-an-li
评论